#ai-observability
#ai-observability
[ follow ]
#observability #ai #opentelemetry #kubernetes #software-development #incident-response #ai-integration #automation









#opentelemetry

DevOps
fromDevOps.com
3 weeks agoHow eBPF and OpenTelemetry Have Simplified the Observability Function - DevOps.com
OpenTelemetry eBPF Instrumentation enables automatic observability without manual setup, allowing engineering teams to gain rapid visibility into services and infrastructure while avoiding instrumentation challenges.

DevOps
fromDevOps.com
3 weeks agoHow eBPF and OpenTelemetry Have Simplified the Observability Function - DevOps.com
OpenTelemetry eBPF Instrumentation enables automatic observability without manual setup, allowing engineering teams to gain rapid visibility into services and infrastructure while avoiding instrumentation challenges.
Business intelligence
fromDevOps.com
1 month agoWhy OpenTelemetry Is Paving the Way for the Rise of the Observability Warehouse - DevOps.com
OpenTelemetry adoption drives observability architecture toward unified warehouse models that centralize logs, metrics, and traces for scalable, cost-effective real-time operational intelligence.
#log-management
DevOps
fromNew Relic
1 month agoLogs Intelligence Evolution: No Silos. Visibility. Zero Code
New Relic introduces Federated Logs and no-code parsing to enable local log querying while maintaining compliance, reducing troubleshooting time from hours to minutes without data movement or manual regex work.
fromDevOps.com
1 month agoWhat to do About AI's Forced Rethink of Reliability in Modern DevOps - DevOps.com
For years, reliability discussions have focused on uptime and whether a service met its internal SLO. However, as systems become more distributed, reliant on complex internet stacks, and integrated with AI, this binary perspective is no longer sufficient. Reliability now encompasses digital experience, speed, and business impact. For the second year in a row, The SRE Report highlights this shift.
Software development
Node JS
fromThe NodeSource Blog - Node.js Tutorials, Guides, and Updates
5 months agoIntelligent Observability: How AI is Transforming Node.js Telemetry into Actionable Optimization
N|Sentinel uses AI integrated with N|Solid to detect Node.js anomalies, analyze runtime behavior, and provide real-time actionable insights to prevent performance issues.
DevOps
fromInfoQ
2 weeks agoQCon London 2026: Wrangling Telemetry at Scale, a Guide to Self-Hosted Observability
Self-hosted observability stacks require significant resources and expertise; organizations should exhaust all alternatives before building internally, requiring 2-3 full-time engineers and substantial funding.
DevOps
fromInfoQ
2 weeks agoQCon London 2026: Uncorking Queueing Bottlenecks with OpenTelemetry
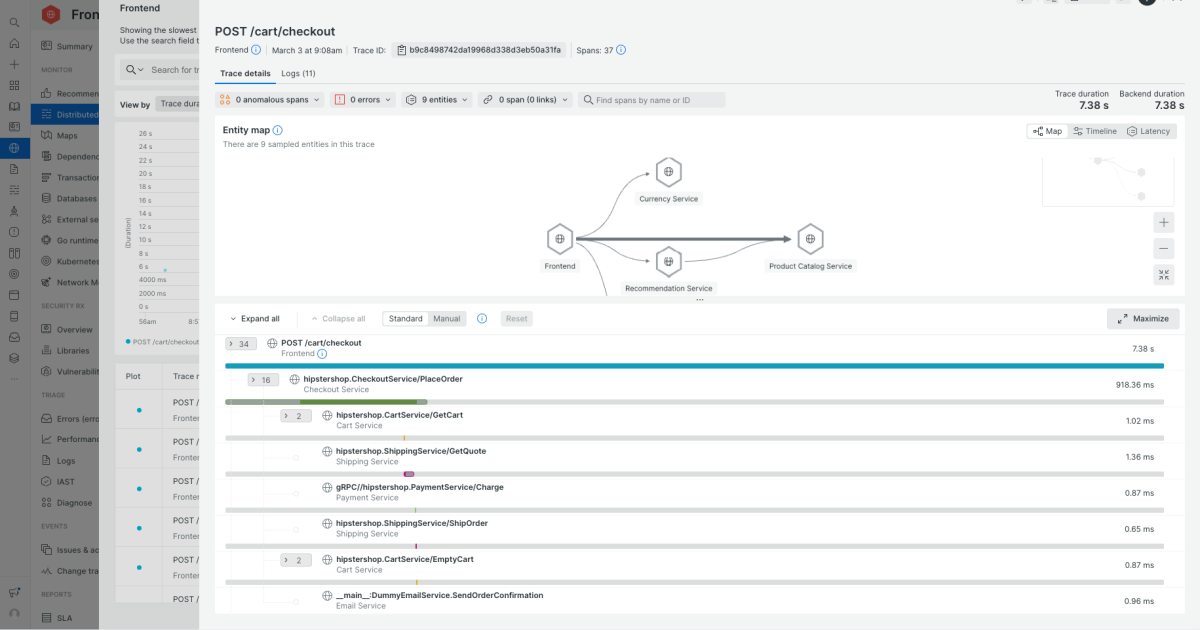
Distributed tracing with OpenTelemetry enables engineers to identify root causes across service boundaries by maintaining hierarchical visibility of operations, while SLOs based on latency provide more reliable alerting than infrastructure metrics.


fromNew Relic
2 months agoThe Power and Cost of Data Cardinality
The more attributes you add to your metrics, the more complex and valuable questions you can answer. Every additional attribute provides a new dimension for analysis and troubleshooting. For instance, adding an infrastructure attribute, such as region can help you determine if a performance issue is isolated to a specific geographic area or is widespread. Similarly, adding business context, like a store location attribute for an e-commerce platform, allows you to understand if an issue is specific to a particular set of stores
Data science
fromDevOps.com
3 weeks agoZero Downtime Multicloud Migrations for Observability Control Planes - DevOps.com
An observability control plane isn't just a dashboard. It's the operational authority system. It defines alert rules, routing, ownership, escalation policy, and notification endpoints. When that layer is wrong, the impact is immediate. The wrong team gets paged. The right team never hears about the incident. Your service level indicators look clean while production burns.
DevOps
DevOps
fromNew Relic
3 weeks agoeBPF Network Metrics for Kernel-Level Observability | New Relic
New Relic's eBPF-based agent unifies network performance, APM telemetry, infrastructure metrics, and logging into a single lightweight solution, eliminating network blind spots and reducing mean time to innocence during incidents.
fromNew Relic
2 months agoPreventing network outages: How we use New Relic to monitor our multi-cloud infrastructure
Running a global observability platform means one thing above all: your infrastructure must never go down. When you're responsible for monitoring thousands of customers' applications 24/7, network failures aren't just inconvenient, they're existential threats. At New Relic, hundreds of clusters run on multiple clouds, and regions. These clusters depend on a complex web of network connections: regional transit gateways, inter-regional hubs, and cross-cloud links.
DevOps
fromNew Relic
1 month ago5 Best Application Performance Monitoring Tools to Consider in 2026
Support for distributed systems. Check how well the tool handles microservices, serverless, and Kubernetes. Can you follow a request across services, queues, and third-party APIs? Does it understand pods, nodes, clusters, and autoscaling events, or does it treat everything like a static host? Correlation across metrics, logs, and traces. In an incident, you shouldn't be copying IDs between tools. Look for the ability to pivot directly from a slow trace to relevant logs,
DevOps
[ Load more ]