DevOps
fromInfoQ
1 day agoReplacing Database Sequences at Scale Without Breaking 100+ Services
Validating requirements can simplify complex problems, and embedding sequence generation reduces network calls, enhancing performance and reliability.
Rhyne's attack involved unauthorized remote desktop sessions, deletion of network administrator accounts, and changing of passwords, showcasing significant security vulnerabilities.
We are making sure that we have renewable energy powering all of our datacentre footprint. We have 100% renewable power today that is powering all of Azure, and we're very proud to build that base and essentially stimulate renewable energy around the world and in the UK.
While the codebase is fresh and grows fast under the umbrella of the local environment, we tend to rely on debugging tools, which were created specifically for that purpose. The app is half-baked, and the code is split open. We observe it through the lens of our IDE and with the speed of our brain. Everything is possible; we may pause execution for minutes, and the whole system is a white box - an open book for us.
It was the time of Novell networks, RG58 cables, and bulky tower PCs. It was also a time before the telemarketer's IT department employed specialists. Carter and his two colleagues - boss Mike and part-time student Stefan - therefore handled tasks ranging from programming to support, and everything in between.
Kacper Borucki blogged about parameterizing exception testing, and linked to pytest docs and a StackOverflow answer with similar approaches. The common way to test exceptions is to use pytest.raises as a context manager, and have separate tests for the cases that succeed and those that fail. Instead, this approach lets you unify them. I tweaked it to this, which I think reads nicely: One parameterized test that covers both good and bad outcomes. Nice.
There is a growing emphasis on database compliance today due to the stricter enforcement of compliance rules and regulations to safeguard user privacy. For example, GDPR fines can reach £17.5 million or 4% of annual global turnover (the higher of the two applies). Besides the direct monetary implications, companies also need to prioritize compliance to protect their brand reputation and achieve growth.
Which Algorithm Is This? If you step back, this maps almost perfectly to the Top K Frequent Elements problem.We usually solve it for integers in a list. Here, the "elements" are audience profiles age and body-type combinations. First, define what an audience profile looks like: case class Profile(age: Int, height: Int, weight: Int) What we want is a function like this:
Constructing datacenters accounts for 39 percent of their total carbon dioxide emissions, almost as much as operating them, according to an environmental analysis covering the entire lifecycle of a facility. The finding comes from a white paper published by European datacenter operator Data4, which conducted a lifecycle assessment (LCA) of one of its own facilities with the assistance of design and engineering consultants APL Data Center.
The more attributes you add to your metrics, the more complex and valuable questions you can answer. Every additional attribute provides a new dimension for analysis and troubleshooting. For instance, adding an infrastructure attribute, such as region can help you determine if a performance issue is isolated to a specific geographic area or is widespread. Similarly, adding business context, like a store location attribute for an e-commerce platform, allows you to understand if an issue is specific to a particular set of stores
This extends to the software development community, which is seeing a near-ubiquitous presence of AI-coding assistants as teams face pressures to generate more output in less time. While the huge spike in efficiencies greatly helps them, these teams too often fail to incorporate adequate safety controls and practices into AI deployments. The resulting risks leave their organizations exposed, and developers will struggle to backtrack in tracing and identifying where - and how - a security gap occurred.
For any IT department, these four words are the beginning of a familiar, often frustrating, journey. In our modern world, where business success is built on distributed applications and hybrid cloud architectures, the network is the circulatory system. When it fails, everything grinds to a halt. Yet, despite its critical importance, it often remains a black box-a source of blame that is difficult to prove or disprove.
AI systems continued to advance rapidly over the past year, but the methods used to test and manage their risks did not keep pace, according to the International AI Safety Report 2026. The report, produced with inputs from more than 100 experts across over 30 countries, said that pre-deployment testing was increasingly failing to reflect how AI systems behaved once deployed in real-world environments, creating challenges for organisations that had expanded their use of AI across software development, cybersecurity, research, and business operations.
At that point, backpressure and load shedding are the only things that retain a system that can still operate. If you have ever been in a Starbucks overwhelmed by mobile orders, you know the feeling. The in-store experience breaks down. You no longer know how many orders are ahead of you. There is no clear line, no reliable wait estimate, and often no real cancellation path unless you escalate and make noise.
Manual database deployment means longer release times. Database specialists have to spend several working days prior to release writing and testing scripts which in itself leads to prolonged deployment cycles and less time for testing. As a result, applications are not released on time and customers are not receiving the latest updates and bug fixes. Manual work inevitably results in errors, which cause problems and bottlenecks.
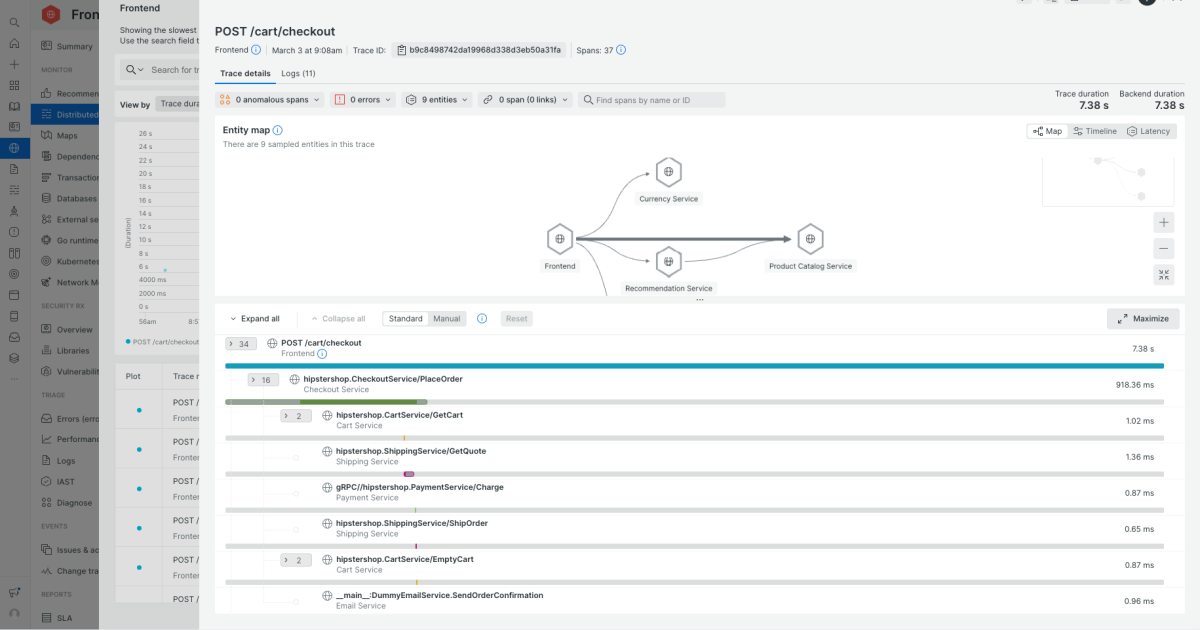
Support for distributed systems. Check how well the tool handles microservices, serverless, and Kubernetes. Can you follow a request across services, queues, and third-party APIs? Does it understand pods, nodes, clusters, and autoscaling events, or does it treat everything like a static host? Correlation across metrics, logs, and traces. In an incident, you shouldn't be copying IDs between tools. Look for the ability to pivot directly from a slow trace to relevant logs,
If you're trying to make sure your software is fast, or at least doesn't get slower, automated tests for performance would also be useful. But where should you start? My suggestion: start by testing big-O scaling. It's a critical aspect of your software's speed, and it doesn't require a complex benchmarking setup. In this article I'll cover: A reminder of what big-O scaling means for algorithms. Why this is such a critical performance property.
To find the typical example, just observe an average stand-up meeting. The ones who talk more get all the attention. In her article, software engineer Priyanka Jain tells the story of two colleagues assigned the same task. One posted updates, asked questions, and collaborated loudly. The other stayed silent and shipped clean code. Both delivered. Yet only one was praised as a "great team player."